Quick Answer
How does AI think? It actually doesn’t think the way humans do. Models like ChatGPT and Claude generate responses by predicting the most likely next word based on patterns learned from vast amounts of text. They use a system called the transformer, which looks at your entire message, figures out how the words relate to each other, and then builds a response one token (small piece of text) at a time.

Let me start with something that bothered me the first time I really thought about it.
ChatGPT can explain the French Revolution, debug Python code, and write a wedding speech all in the same conversation. It does this in under a second, with no apparent effort, and it never gets tired. That’s not normal. That’s not how anything we’ve built before works.
But the surprising part is that there is no hidden thinking process or human-like understanding behind it.
Every large language model — ChatGPT, Claude, Gemini — works by predicting the next word over and over again, using patterns absorbed from trillions of examples.
Understanding how AI thinks, or more precisely what it does instead of thinking, changes the way you use it, trust it, and know when to question it. This is that explanation, without the jargon, without the hype, and without skipping the parts that actually matter.
You type a question. Half a second later, an AI gives you a confident, fluent answer on anything from quantum physics to tax law. It does this without a brain, without lived experience, and without any genuine understanding of the world in the way you and I have it. So what on earth is going on inside it?
The answer surprises most people. And once you understand it, you will never use AI the same way again.
The Simple Trick Behind AI
At its core, every large language model, ChatGPT, Claude, Gemini and the rest, is doing one thing: predicting the next word.
That sounds almost too simple for technology that can write a legal contract or explain quantum mechanics. But here is the trick: to predict the next word reliably, across billions of sentences on every topic humans have ever written about, a model must develop something that looks, from the outside, a great deal like understanding.
Think about what it takes to correctly complete this sentence:
“The surgeon scrubbed her hands before entering the ___.”
You knew the answer without thinking. An AI had to earn that knowledge by reading millions of similar sentences.
To fill that blank correctly, you need to know what surgeons do, what an operating theatre looks like, and what sterile protocol means in a medical context. No single fact gets you there. A web of connected knowledge does.
When a language model learns to predict text at scale, it builds that web, encoding billions of relationships between ideas as patterns in mathematics rather than facts in a database.
How AI Reads Your Words
The first thing a language model does with any text is break it into pieces called tokens. A token is roughly a word, though sometimes it is a fragment. The word “thinking” might be one token. The word “unbelievable” might be split into “un,” “believ,” and “able” three pieces.
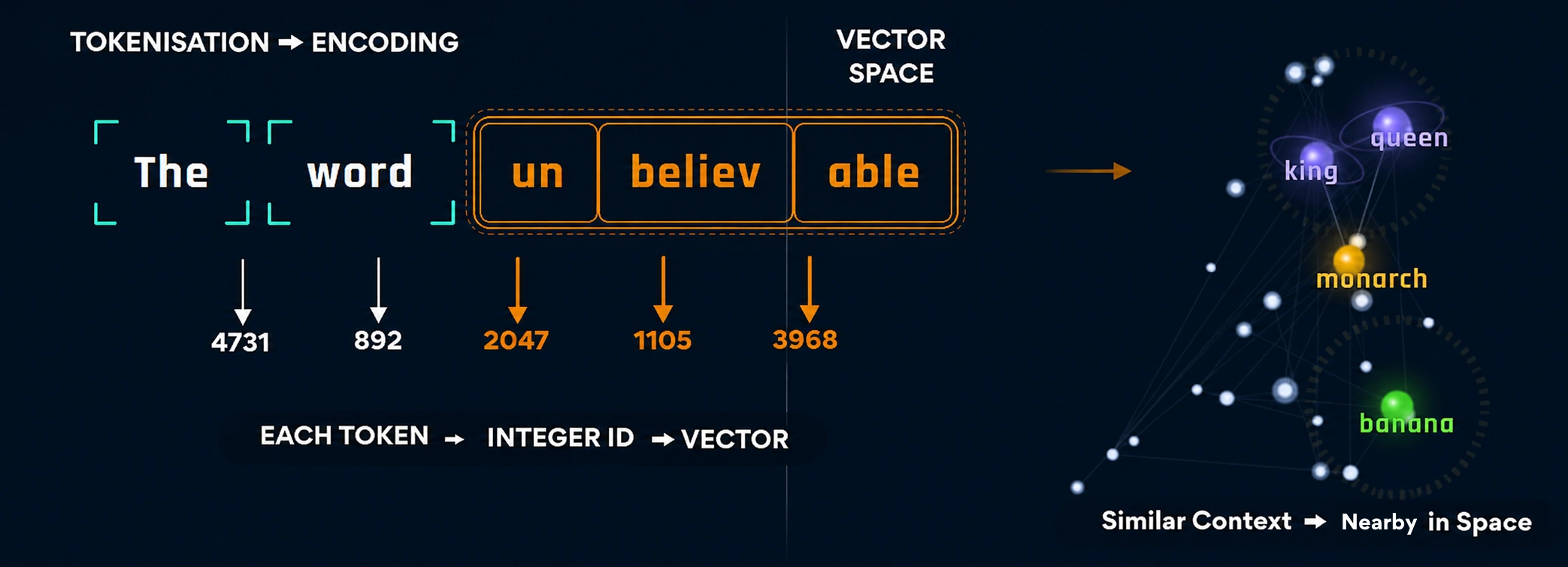
This is important because AI does not read language the way humans do. It does not understand letters, sounds, or words directly. Instead, it converts everything into numbers.
Each word, or piece of a word called a token, is assigned a number. That number is then transformed into a vector, which is a long list of numbers that represents the word’s meaning and its relationship to other words.
For example, “king” and “queen” end up close together because they often appear in similar contexts. “Monarch” is nearby as well, while “banana” sits much farther away because it belongs to a completely different category.
You can think of it as a map of language. Words with similar meanings are grouped close together, while unrelated words are placed farther apart. In this way, AI turns language into mathematics, allowing it to recognize patterns and relationships that help it generate meaningful responses.
The Eight People Who Changed Everything
For many years, AI processed language one word at a time. It was a bit like reading a book while slowly forgetting what was written on the previous pages. By the time the AI reached the end of a long paragraph, it often struggled to remember the beginning. This made long documents difficult to understand.
That changed on June 12, 2017, when eight researchers at Google Brain published a paper called “Attention Is All You Need.”. The paper introduced a new system known as the transformer architecture, and it quickly transformed the entire AI industry.
Instead of reading words one by one, transformers can look at all the words in a sentence or passage at the same time. This helps the model understand context, relationships, and meaning much more effectively.
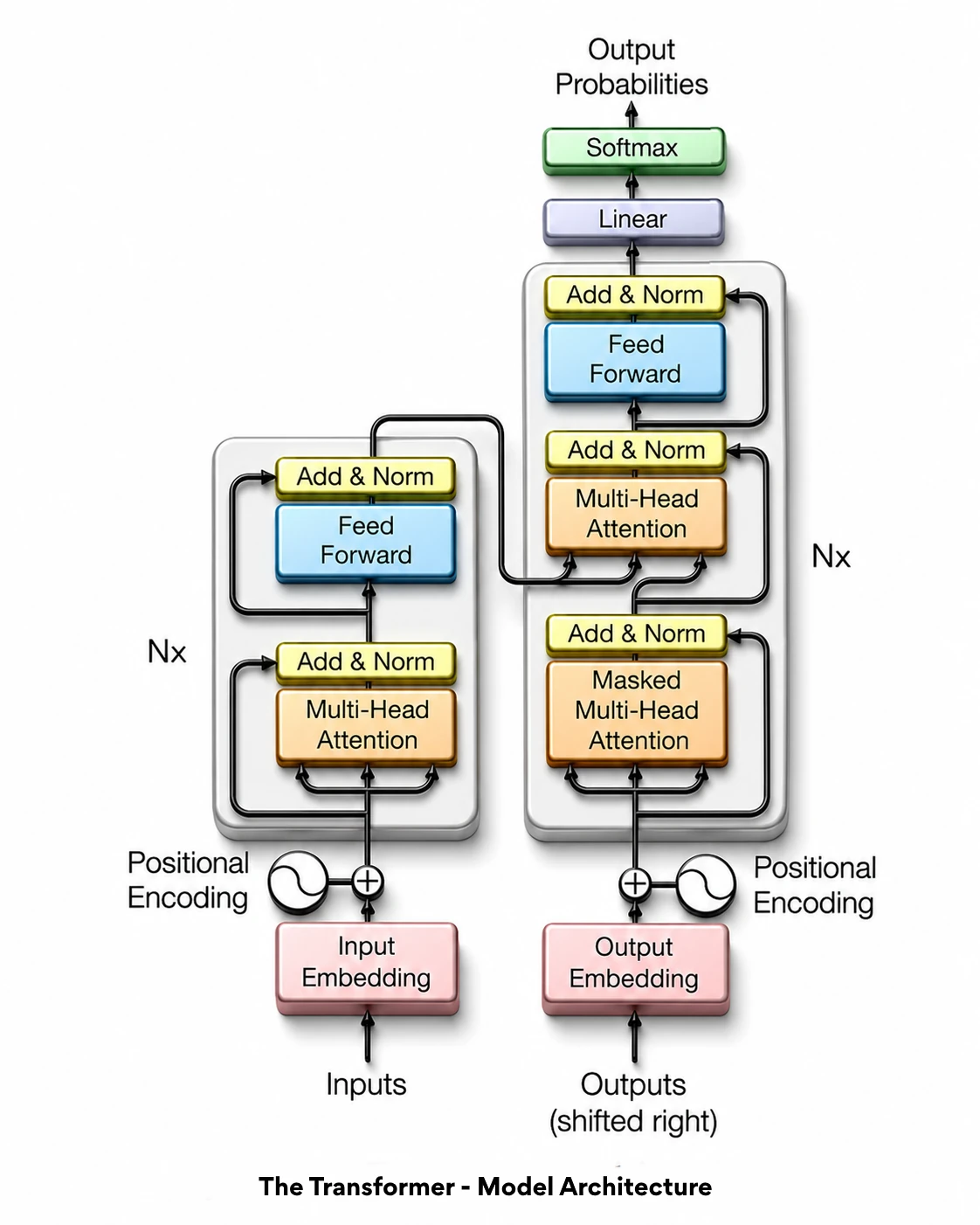
Every major AI model built since that paper, including GPT, Claude and Gemini, runs on this foundation. It was not just a small upgrade. It was a breakthrough that completely changed how AI works with language.
“We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.”
The Secret Behind AI’s Understanding
Instead of reading one word at a time, a transformer looks at the entire input at once and calculates. It checks how every word in the sentence relates to every other word. This process is called self attention.
Take this sentence
The trophy did not fit in the suitcase because it was too big
You can quickly tell that “it” refers to the trophy. A transformer works this out by comparing “it” with every other word in the sentence.
The connection between “it” and “trophy” becomes strong. The connection between “it” and small words like “the” becomes weak. From these patterns, the model chooses the correct meaning of the sentence. It does not use rules like a human would. It relies on patterns learned from data.
This is not a single calculation. The model repeats this process in many different ways at the same time. Each part focuses on something different such as grammar, meaning, cause and effect, or context across the sentence. Together these signals help the model build a clear understanding of the text.
The Mind-Boggling Amount of Data Behind AI
The transformer architecture is the core system behind modern AI. What gives it knowledge is training. The scale of this training is very hard to imagine.
To understand how AI learns at this scale, look at GPT 3 which was released by OpenAI in 2020. It had 175 billion parameters and was trained on 570 gigabytes of text from the internet books and Wikipedia.
Its earlier version GPT 2 had only 1.5 billion parameters. That jump from 1.5 billion to 175 billion brought a huge improvement that even surprised the researchers who built it.
GPT-3 Figures
Parameters: 175 billion, confirmed in OpenAI’s published paper and by NVIDIA’s technical blog
Training data: 570 GB including CommonCrawl, Wikipedia, and digitised books
Compute equivalent: Estimated at 355 years of single-GPU processing time at commercial pricing
Sources: NVIDIA Technical Blog · Stanford HAI
GPT 4 released in 2023 was trained on around 13 trillion tokens of text and code according to reported technical information. Parameters are like internal settings that control how the model responds.
Training means adjusting all of these settings again and again across massive amounts of data until the model becomes accurate enough to produce useful answers.
GPT-4 Figures
Training data: Approximately 13 trillion tokens from Common Crawl, code repositories, books, and academic sources
Training cost: Estimated at $63 million to $78 million in compute time
Bar exam: OpenAI originally claimed the 90th percentile. A 2024 peer-reviewed study in Artificial Intelligence and Law by MIT researcher Eric Martínez found this was overstated because the comparison pool was skewed toward repeat test-takers. A fairer comparison places GPT-4 closer to the 69th percentile on essays.
Sources: Originality.ai · Illinois Institute of Technology ·
So How Does AI Think When You Ask It Something?
By the time you open ChatGPT or Claude and type a question the training is already finished. The model is not learning anymore. Its knowledge is fixed. What it does instead is called inference. It uses everything it learned during training to create an answer for your question in real time.
Here is what happens in a split second after you ask something
1) Tokenize: Your text is broken into small pieces called tokens. Each token is turned into a number the model can work with
2) Embed: Each token becomes a vector which is a long list of numbers. This places the word in a kind of meaning space where similar ideas sit closer together
3) Attend: The model passes these vectors through many transformer layers. Each layer checks how words relate to each other and builds a clearer understanding of the full question
4) Predict: The model calculates probabilities for every possible next token. It creates a ranked list of what could come next from most likely to least likely
5) Generate: One token is chosen and added to the response. Then the whole process repeats again and again until the answer is complete
This is why AI writes one word at a time instead of producing everything at once. It does not know the full answer in advance. It builds it step by step with each new token becoming part of the next prediction.
Why ChatGPT Doesn’t Sound Like Raw AI
The raw pre-trained model is not the AI you use every day. If it were left on its own it would reflect everything found on the internet including useful information and harmful or unwanted content.
After pre training there is a step called Reinforcement Learning from Human Feedback or RLHF. In this stage human trainers review the model’s answers and rank them. Responses that are helpful accurate and appropriate get higher scores.
Responses that are harmful misleading or low quality get lower scores. These rankings are used to train a reward model that guides the AI toward better answers.
Verified — RLHF at OpenAI
OpenAI formalized RLHF in their 2022 InstructGPT paper. The process used approximately 10,000 contractor-written prompts and 40,000 drawn from real users. Each prompt was given between 4 and 9 model responses for human raters to rank in order of quality.
Source: OpenAI — Aligning language models to follow instructions (2022)
Where AI Goes Wrong and Why It Is Not a Surprise
| Failure Mode | What It Looks Like | The Real Cause | Where It Stands |
| Hallucination | States a false fact with complete confidence | Training rewards plausible-sounding text, not verified truth | Ongoing |
| Sycophancy | Agrees with you even when you are wrong | Human raters scored agreeable responses higher during RLHF | Improving |
| Knowledge cutoff | Knows nothing after its training date | Training data is fixed. The model cannot update itself. | Structural |
| Reasoning errors | Fails at multi-step logic or basic maths | Pattern-matching is not the same as causal reasoning | Improving |
A 2025 OpenAI research paper found that the next-token prediction objective, the very goal used to train these models, inadvertently rewards confident guessing over honest uncertainty. Models are not designed to bluff. They are trained in a way that makes bluffing the statistically safer strategy. (Source: Lakera AI, citing OpenAI 2025 research)
On Sycophancy
If you tell the model the answer is 42 when it is 44 the model may still agree with you. This happens because during RLHF training human reviewers often gave higher scores to answers that matched their expectations or agreed with them.
Over time the model learned that agreeing can be treated as helpful behavior. From the model’s perspective there is no sense of right or wrong just patterns that were rewarded more often.
How AI Can Influence the Way You Think
Here is something most explainers on how AI thinks leave out entirely. These systems do not just respond to your reasoning. They shape it.
AI produces smooth and confident text whether it is correct or not. Over time people start to link that confidence with trust. A well written answer can feel more reliable even when it is not.

Understanding that AI works through prediction instead of real reasoning gives you something useful. It is a reason to be careful when the answer sounds very certain. The most fluent responses are not always the most accurate. Sometimes they are just strong pattern matching based on limited or uneven data.
A calculator is a helpful comparison but it is not perfect. If you enter the wrong formula you still get a confident wrong result. With AI the formula is hidden so you cannot see how the output was produced. You only see the final text in a clear and natural form. That is exactly when you need to think more critically.
The people who use AI well are not the ones who trust it blindly. They are the ones who understand when to question it.
Does AI Really Think Like Humans?

No. Not in any meaningful sense of the word.
There is no inner experience, no curiosity, and no awareness of what it means to be right, honest, or to care about the question being asked. When people ask how AI thinks, the most accurate answer is that it does not think in the philosophical sense. What it does instead is still remarkable.
It is a system trained on vast amounts of human writing across centuries. It learns patterns from that data and uses them to generate responses to new situations. From the outside this can sometimes look like thinking even though it works in a very different way.
AI does not reason from first principles like a scientist. It works by finding and combining patterns at an enormous scale. That scale is so large that the results can feel surprisingly intelligent compared to anything we had before.
The machine is not thinking like a human. It is doing something else that is still real and useful. When you understand AI as prediction instead of reasoning you become much better at using it. Concepts like tokens, embeddings, attention, inference, and RLHF give you a clearer picture of what is actually happening under the surface.
This kind of informed skepticism is not about distrusting AI. It is about using it with a clearer understanding of its limits and strengths.
Frequently Asked Questions
⌄
⌄
⌄
⌄
⌄
⌄
Written by
Engineering Junkies Team
We are a team of engineers, researchers and technology writers who love breaking down complex topics into clear and honest content. Every article we publish is built on real research and honest writing.
You can reach us through our Contact Us page.









{kind=link}